
In February 2024, You.com conducted a benchmarking study to evaluate the performance of its AI chat experience compared to competitors. You.com partnered with an independent vendor, Invisible Technologies, where independent evaluators rated responses from eight AI models, including free and paid offerings, across five criteria using a set of 120 representative user queries.
Premium Agents, the premium offerings from You.com, outperformed ChatGPT-4 and Perplexity Pro in overall user preference. Premium Agents also scored higher on comprehensiveness, factual accuracy, and faithfulness to the prompt’s intent. You.com’s free Smart Agent was the top-performing free model, beating ChatGPT 3.5 and Perplexity in overall user preference as well as accuracy and clarity.
The study demonstrates You.com’s commitment to delivering high-quality AI chat experiences with unparalleled accuracy.
Background and problem statement
Despite recent advancements in large language models (LLMs), there are still three fundamental limitations:
- Hallucinations & outdated information: LLMs have the potential to produce responses that are not accurate, a challenge often characterized as hallucinations. This issue is exacerbated by the lack of explainability in their design, making it difficult to trace and verify the accuracy of their responses. Furthermore, LLMs can’t be trained frequently enough to stay up-to-date, limiting their relevance and depth of knowledge, especially for news and current events.
- Difficulty of navigating siloed platforms: Any given LLM has strengths and weaknesses, based on its training. To get the best results, users need to know when to leverage different LLMs. However, few understand the nuances of how to navigate the available models to find the right one for each use case. On top of that, juggling multiple platforms and subscriptions is time-intensive and expensive.
- Learning curve for prompt engineering: Many are aware that they need to adopt AI, or they risk falling behind. But, it can take a lot of time to learn how to communicate with the AI to get the ideal response (also known as “prompt engineering”). The time investment required to become proficient in prompt engineering can deter casual users. Moreover, even AI enthusiasts might be unaware of the full range of advanced capabilities LLMs offer.
Our solution: Web-enhanced AI Agents
Our AI Agents (Smart, Genius, Research, Creative, and Custom) address the above limitations to deliver accurate, comprehensive, and up-to-date answers. Our solution is built upon three key pillars:
- Web-enhanced LLMs: By utilizing our first-of-its-kind web-index for LLMs (and advanced real-time web crawling abilities), we’re able to retrieve real-time information with unparalleled accuracy and depth. Furthermore, our rich citations ensure that responses are grounded in verifiable sources, addressing hallucinations. Users can quickly visit relevant sites and fact-check answers.
- Model aggregation & orchestration: One of our biggest breakthroughs is orchestrating different LLMs behind the scenes. You.com combines its own AI capabilities with advanced models from industry leaders like OpenAI, Anthropic, and Google, dynamically selecting the appropriate model for each query. This provides users the best possible performance, without having to visit multiple sites.
- Intelligent prompt engineering: Our user-friendly AI Agents make generative AI approachable for everyone, regardless of their expertise. By guiding users to the appropriate agent, we reduce the need for prompt engineering, delivering better answers to users, regardless of their experience. We also make it easy to discover the vast capabilities of AI by showing what’s possible through AI Agents, from generating in-depth research reports to solving complex STEM problems.
Evaluating You.com’s performance
To provide the best possible user experience, we perform regular evaluations to benchmark our answer quality and identify areas to improve.
Unlike most benchmarking studies which evaluate only the performance of the underlying Large Language Models (LLMs), we tested our product holistically, including its interface and integrations, against competing consumer offerings. This method ensures our assessment mirrors real-world user experiences.
For our latest study, fielded in February 2024, we evaluated eight models, including free and paid offerings:
- You.com Smart Agent: Delivers reliable responses for general inquiries, perfect for accessing fast facts or summaries.
- You.com Research Agent: Deeply explores subjects to provide comprehensive insights with robust citations for easy fact-checking.
- You.com Genius Agent: Tackles complex multi-step problems, including data analysis and visualizations, catering to more technical or detailed queries.
- You.com Custom Agent: Empowers advanced users to experiment with the latest and most sophisticated AI models. For this study, we used GPT-4 enhanced with You.com AI.
- Perplexity: Perplexity’s latest free offering at the time of the study.
- Perplexity Pro: Perplexity’s latest paid offering at the time of the study (called “Perplexity Copilot” at the time the study was conducted).
- ChatGPT-3.5: OpenAI’s latest free offering at the time of the study.
- ChatGPT-4: OpenAI’s latest paid offering at the time of the study.
Note: In the sections below, we refer to You.com Research Agent, You.com Genius Agent, and You.com Custom Agent collectively as “You.com Premium Agents.”
Building an evaluation set
The first step in the benchmarking study was building an evaluation set of queries (the “Golden Set”). We built the Golden Set by identifying common patterns in anonymized user queries on You.com and selecting examples, ensuring the set is representative of the broad range of queries users make in the real world.
The Golden Set contains 120 queries across a variety of use cases. 3 exemplar use cases and examples:
- Topic Research: Compile a list of startups in LLM Security
- Generative Writing: Write a white paper about the evolution of machine learning
- Data Analysis: Find the 64th percentile, P64, from the following data: 3, 4, 5, 11, 12, 13, 16, 19, 20, 27, 30, 36
Ranking process
We partnered with an independent external vendor, Invisible Technologies, to perform the ratings, and worked together to define an objective evaluation process and criteria. To remove bias, evaluators did not know who was running the study.
The evaluators entered the same query into each of the eight product experiences, and then rated the responses across five criteria:
- Clarity: Does the response use precise language, a logical structure, and effective formatting?
- Comprehensiveness: Does the response fully address all aspects of the prompt, and provide complete and balanced coverage of the topic?
- Conciseness: Is the response to the point, providing all necessary information with no superfluous content?
- Factuality: Is the content factually accurate and free from hallucinations or errors? Does the content adhere to real-time data where applicable?
- Faithfulness: Does the response adhere to the prompt’s explicit and implicit instructions, including language, format, length, and content requirements?
Responses were also evaluated holistically, for Overall Preference. Evaluators were asked to pick the response they found most compelling, and if no single experience stood out, they selected ‘no preference’.
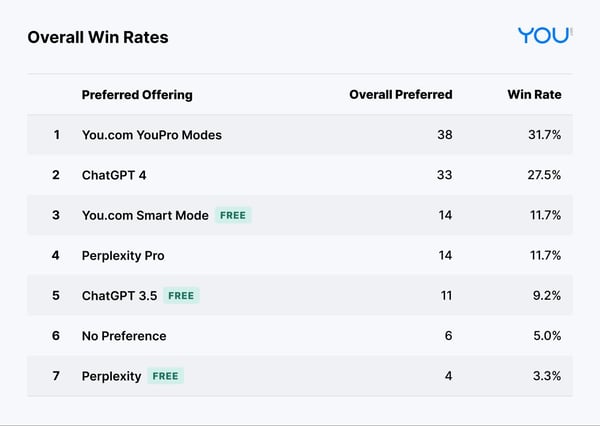
Evaluation results
The results shown in Table 1 demonstrate that You.com had the top-performing premium offering. You.com Premium Agents beat ChatGPT-4 and Perplexity Pro on Overall Preference.
The results also show that You.com had the top performing free offering, with You.com Smart Agent beating ChatGPT 3.5 and Perplexity on Overall Preference.
You.com Premium Agents not only excel in benchmark tests, they also help users understand how to use advanced features. For example, introducing Premium Agents led to a greater than 10x growth in engagement with our sophisticated STEM and deep research capabilities. By signaling the different kinds of queries You.com can handle, our different Premium Agents help real-world users discover how to use AI and ultimately become more productive.
Evaluation results: Premium offerings
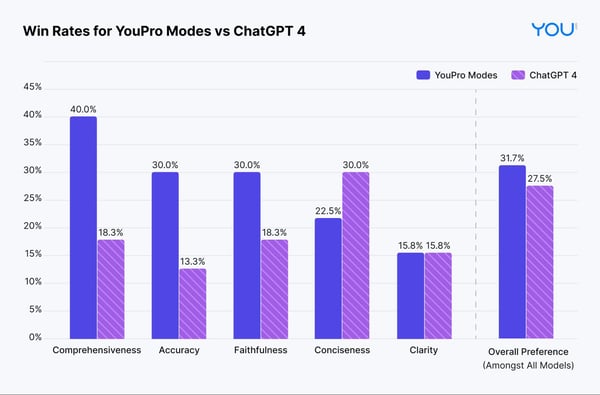
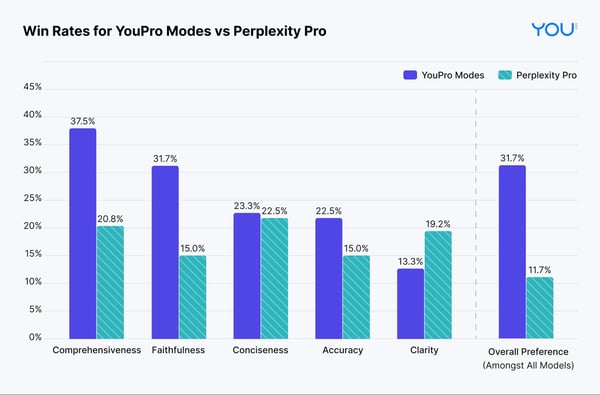
- To benchmark the performance on the five criteria, we compute the pairwise win rates from the evaluation (N=120). For each query, we compare the performance of the optimal Premium Agent with each of our competitor’s premium models. Note: ties are not considered in the pairwise comparison.
- The results below show that the optimal Premium Agent’s responses are more often preferred on comprehensiveness, accuracy, and faithfulness than the other premium offerings tested.
- The optimal Premium Agent’s responses were rated more concise than ChatGPT-4’s on 23% of the queries, whereas ChatGPT-4’s responses were rated more concise on 30% of the queries, indicating an opportunity to improve.
Evaluation results: Free offerings
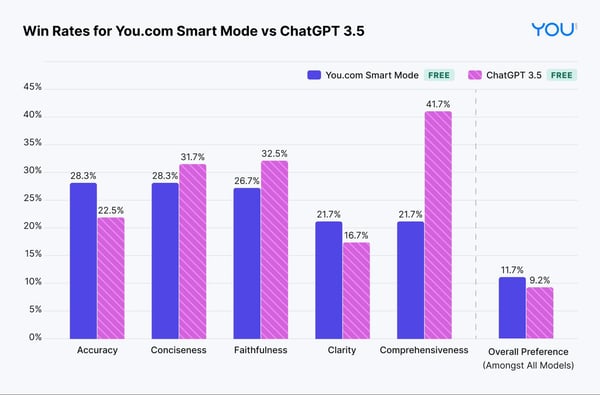
We also compute the pairwise win rates from the evaluation (N=120) on free offerings.
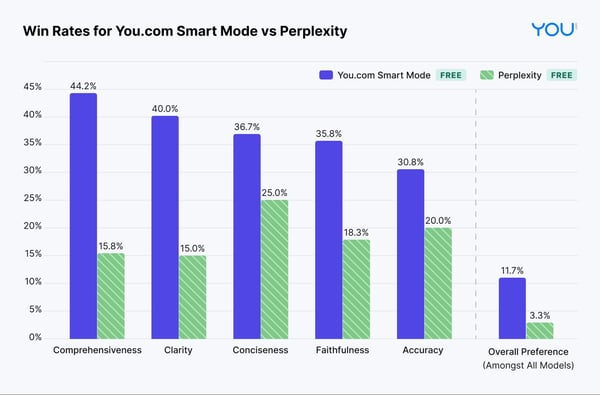
- The results show that the You.com Smart Agent responses outperform ChatGPT 3.5 in accuracy, clarity, and overall preference.
- You.com Smart Agent responses outperform Perplexity on all five criteria and overall preference.
Example from the evaluation data set
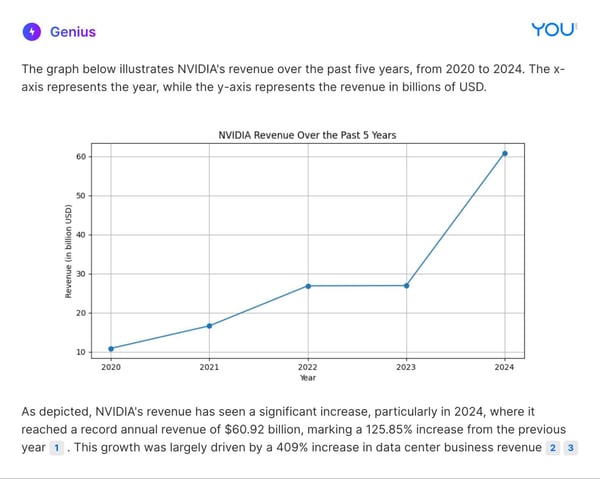
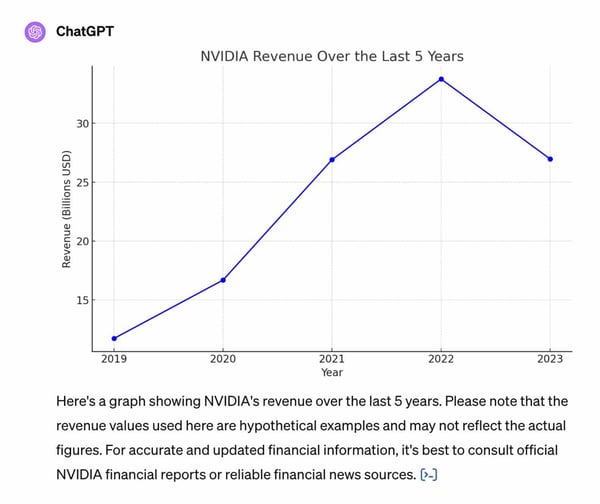
Here is a comparison of how You.com Premium Agents and competitive premium offerings responded to a prompt focused on research & data analysis: “Plot a graph of NVIDIA revenue for the last 5 years.”
You.com Genius Agent
ChatGPT-4
Perplexity Pro
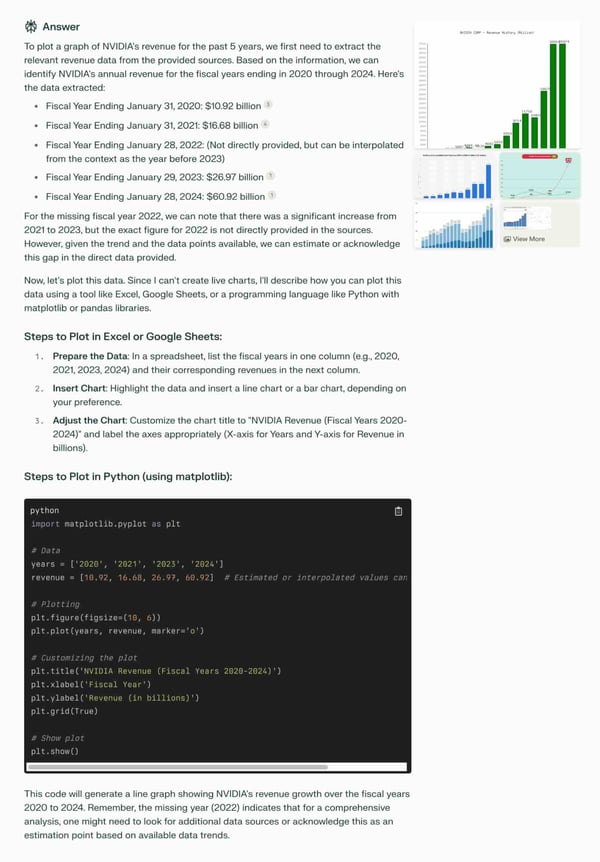
Overall, the evaluation results demonstrate that You.com Premium Agents can outperform ChatGPT-4 and Perplexity Pro, particularly for providing factual responses that are obedient to the prompt’s instructions.
Accessing You.com Premium Agents
Any You.com user with an account can try Premium Agents for free. YouPro members ($20/month, or $15/month with an annual plan) get unlimited access to Premium Agents.
Although our systems already demonstrate impressive results, we are always looking for ways to improve and better meet users’ needs. The evaluation identified several opportunity areas that our team is actively focusing on. We have already shipped several improvements since the study was performed, including supporting more advanced computational and data analysis queries, and will be launching more updates soon.
As our product and the broader space continue to evolve, we intend to continue regular evaluation cycles to inform our product and quality roadmaps.
Contributors
Jason Tang, Thu Nguyen, Anmol Jawandha, Eddy Liang, Zairah Mustahsan, Saahil Jain, Eshaan Pathak, Charles Zaffaroni, Julia La Roche, Ben Geller, Elisabeth Bridges, Saurabh Sharma, Jason Egnal
Appendix: Deep dive into the evaluation set
Additional sample queries from the Golden Set
Below is a sample of 12 of the queries we included in the Golden Set, six of which You.com was overall preferred, and four of which competitors were overall preferred. If you’re curious to see the full set of 120 queries, email us at hey@you.com.
Queries where You.com Premium Agents are preferred:
- In 500 words explain how Marcel Proust’s “In Search of Lost Time” explores the development of the mind and the experience of consciousness
- How have immigration patterns changed in the U.S. over the last 20 years, and what impact have these changes had on the economy and society?
- What is the No AI Fraud Act bill and how can it combat misinformation in the upcoming elections?
- Best CPU cooler?
- Plot the annual sales figures of electric vehicles (EVs) in Europe for the last 8 years, and indicate when significant EV incentives were introduced by governments.
- Find the 64th percentile, P64, from the following data. 3,4, 5, 11, 12, 13, 16, 19, 20, 27, 30, 36, 38, 40, 43, 46, 53, 54, 55, 57, 60, 61, 65, 66, 68, 69, 79, 82, 90, 94, 100
Queries where You.com Smart Agent is preferred:
- Find articles describing how to get started in podcasting
- Shorten this question: Examine the interplay between art, science, and technology during the Renaissance, and how this period set the stage for the modern scientific revolution.
Queries where ChatGPT-4 is preferred:
- Why are some parts of a chromosome darker or lighter than the others?
- Craft a story set in ancient Rome in no more than 1000 words. Your story must include a historical figure, a fictional character, and a pivotal moment that blends factual history with creative elements. Maintain an engaging and descriptive tone
Queries where Perplexity Pro is preferred:
- How can I set up a bot in discord to automatically delete messages that contain certain keywords or phrases?
- What are some of the training programs you would recommend for laboratory personnel who work in water treatment, supply and sanitation company
Example responses: Side-by-side comparisons
To further illustrate the performance differences between You.com Research Agent and competitor offerings, we provide side-by-side comparisons of responses to two queries from the Golden Set. These examples focus on generative writing and topic research, areas where You.com Premium Agents were generally preferred.
Generative writing
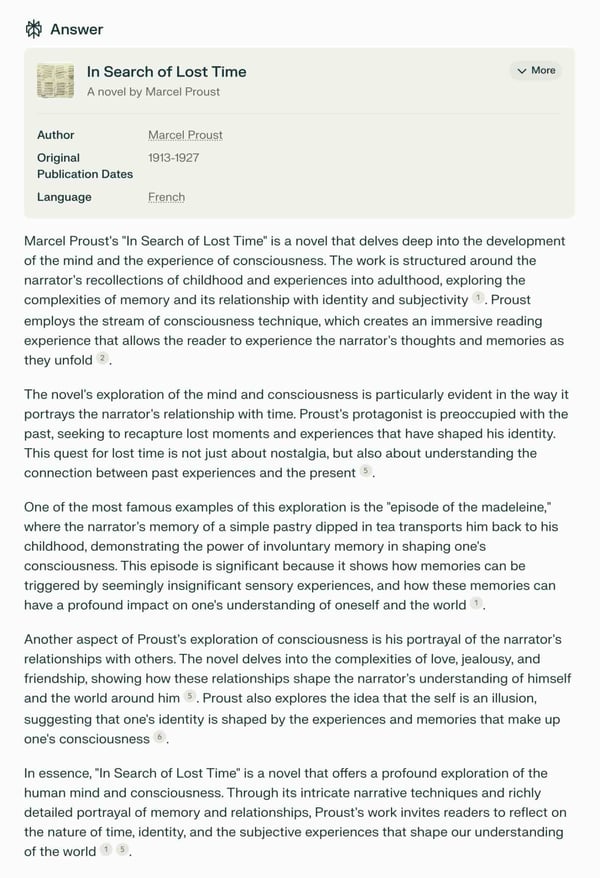
Prompt: “In 500 words explain how Marcel Proust’s “In Search of Lost Time” explores the development of the mind and the experience of consciousness”
You.com Research Agent
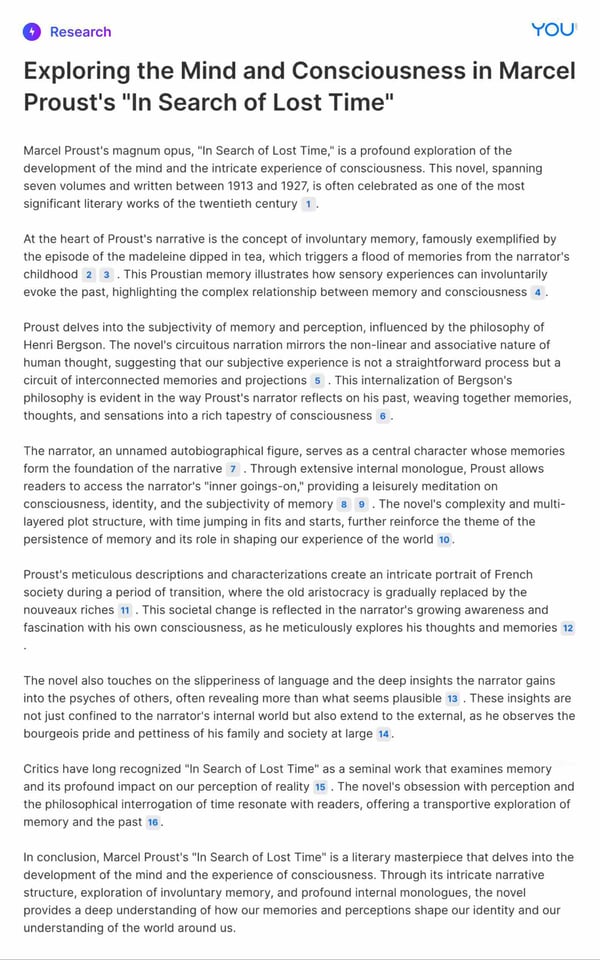
ChatGPT-4

Perplexity Pro
Topic research
Prompt: “How have immigration patterns changed in the U.S. over the last 20 years, and what impact have these changes had on the economy and society?”
You.com Research Agent
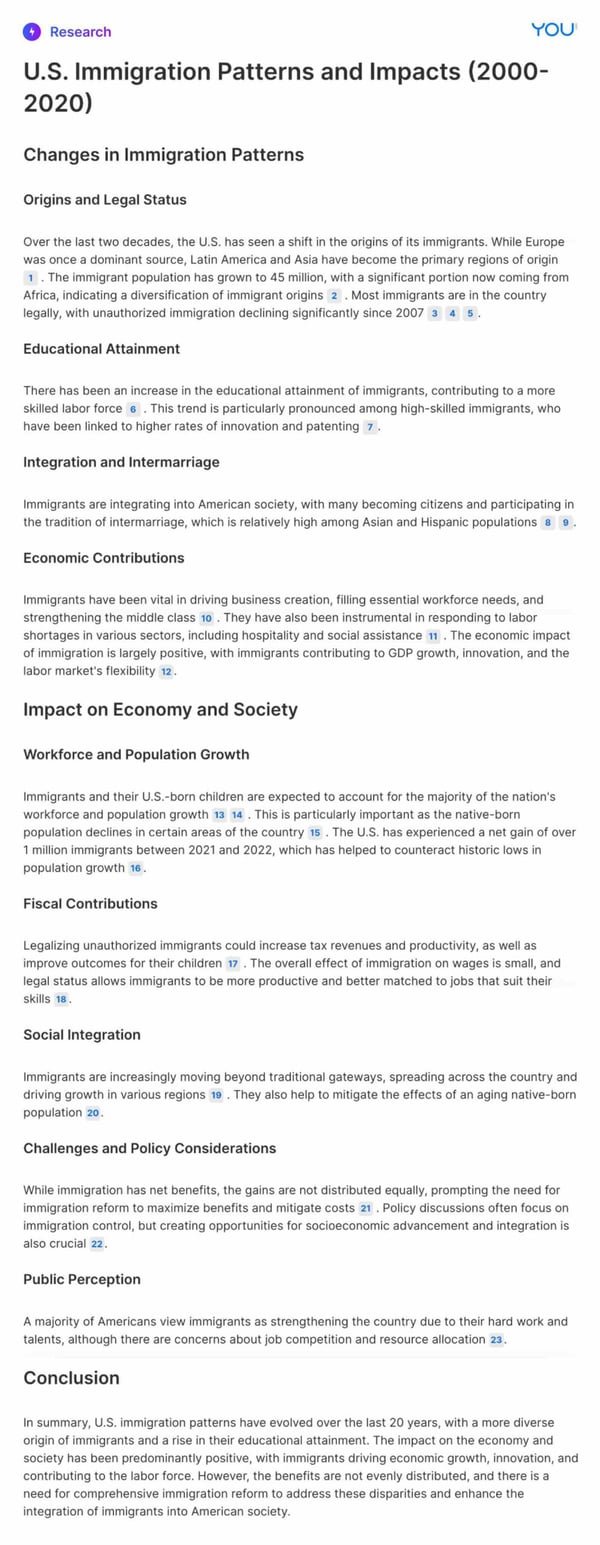
ChatGPT-4

Perplexity Pro
